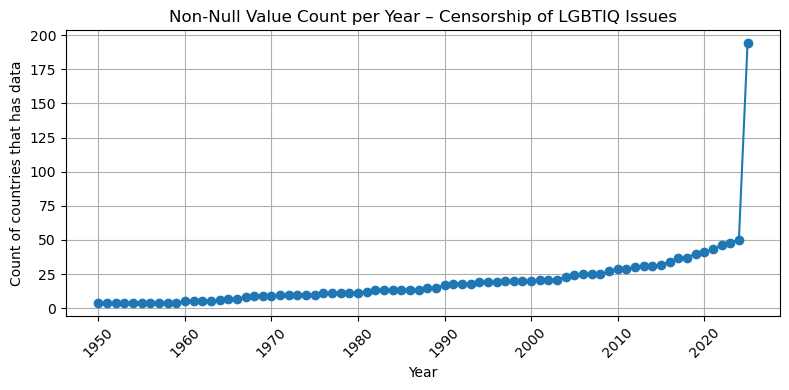
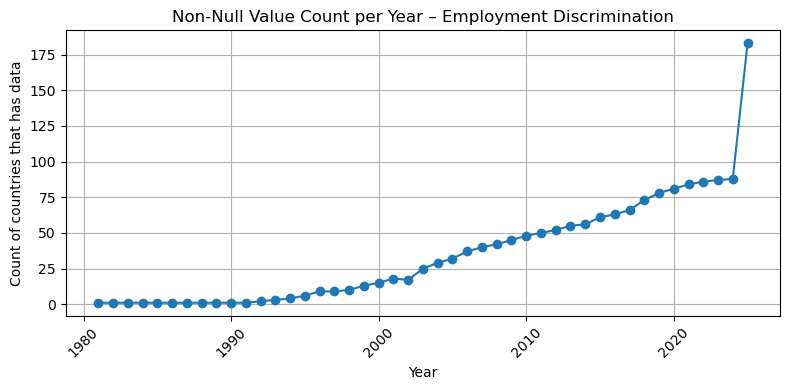
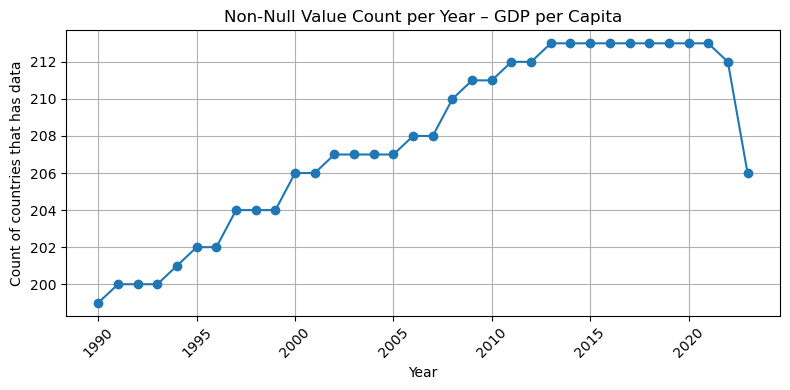
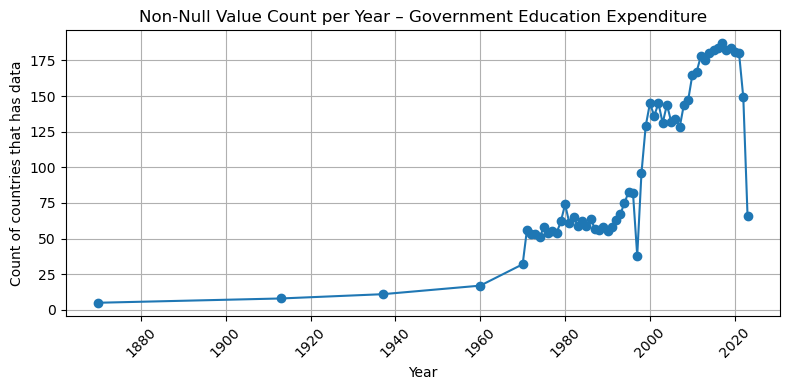
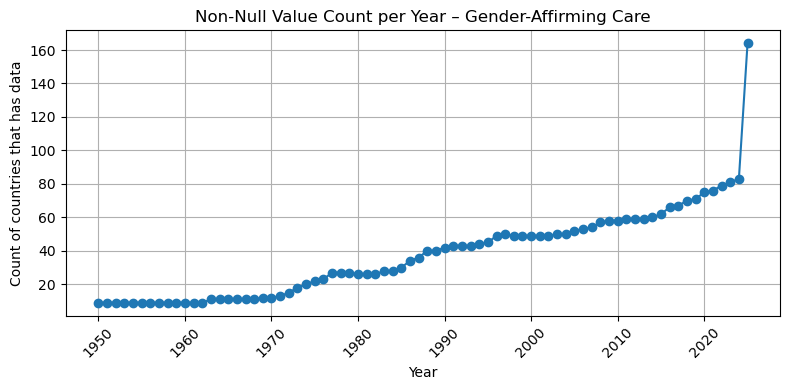
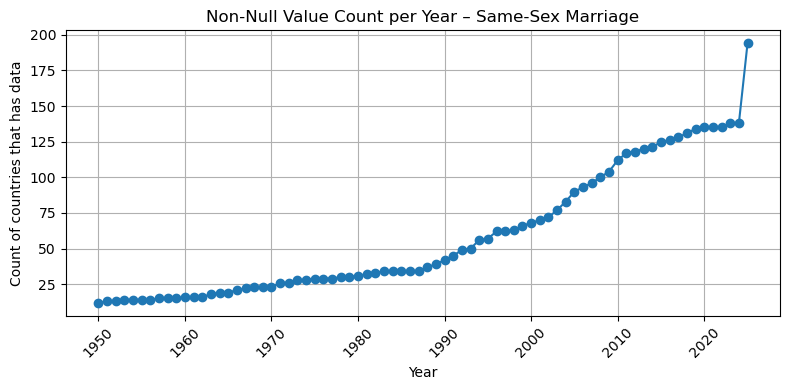
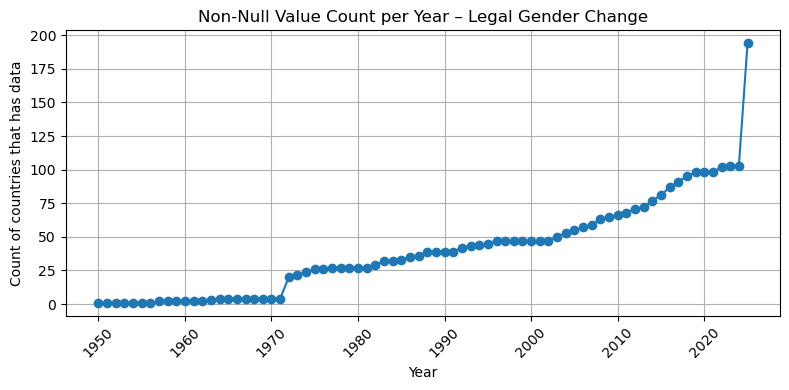
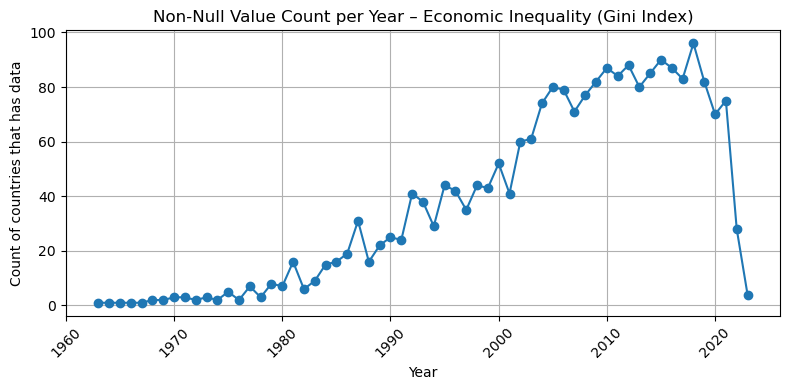import matplotlib.pyplot as pltfor dataset in df["Dataset"].unique(): subset = df[df["Dataset"] == dataset]if subset["num_countries"].notna().sum() ==0:print(f"Skipping {dataset} – all values are null")continue plt.figure(figsize=(8, 4)) plt.plot(subset["Year"], subset["num_countries"], marker='o', linestyle='-') plt.title(f"Non-Null Value Count per Year – {dataset}") plt.xlabel("Year") plt.ylabel("Count of countries that has data") plt.xticks(rotation=45) plt.grid(True) plt.tight_layout() plt.show()
## So based on the result, I think after 2000, we have an acceptable number of countries that have data ( all of them at least have 50 coountires after this year with the valid data)## So I filter the dataset for after 2000, please let me know if you want to change this## This frame would be our base table for our left join ## summary_all
## I've noticed that for some csv files. we do not have code, so I just want to left join on Year and Countrycolumns_to_check = ["Year", "Entity", "Code"]dataframes = {"df_censorship": df_censorship,"df_employment_discrimination": df_employment_discrimination,"df_gini": df_gini,"df_gdp": df_gdp,"df_education": df_education,"df_gender_care": df_gender_care,"df_marriage": df_marriage,"df_legal_gender": df_legal_gender,}for name, df in dataframes.items():print(f"\n{name} - Nulls in Key Columns:")for col in columns_to_check:if col in df.columns: null_count = df[col].isnull().sum()print(f" {col}: {null_count} null(s)")else:print(f" {col}: Column not found")
# First, I combined all datasets into one long DataFrame ## Please notice that stacking all the rows from these datasets on top of each otherall_data = pd.concat([ df_censorship[["Entity", "Code", "Year"]], df_employment_discrimination[["Entity","Code", "Year"]], df_gini[["Entity","Code", "Year"]], df_gdp[["Entity","Code", "Year"]], df_education[["Entity","Code", "Year"]], df_gender_care[["Entity","Code", "Year"]], df_marriage[["Entity","Code", "Year"]], df_legal_gender[["Entity","Code", "Year"]],], ignore_index=True)#### Show rows where 'Code' is nullnull_code_rows = all_data[all_data["Code"].isna()]print(null_code_rows)
Entity Code Year
3108 Argentina (urban) NaN 1980
3109 Argentina (urban) NaN 1986
3110 Argentina (urban) NaN 1987
3111 Argentina (urban) NaN 1991
3112 Argentina (urban) NaN 1992
... ... ... ...
18012 Western and Central Africa (WB) NaN 2018
18013 Western and Central Africa (WB) NaN 2019
18014 Western and Central Africa (WB) NaN 2020
18015 Western and Central Africa (WB) NaN 2021
18016 Western and Central Africa (WB) NaN 2022
[1019 rows x 3 columns]
import pandas as pd## Create a mapping from Entity → Code using non-null valuesentity_to_code_map = ( all_data[all_data["Code"].notna()] .drop_duplicates(subset="Entity") .set_index("Entity")["Code"] .to_dict())## Create lists to store matched and unmatched entity namesmatched_entities = []unmatched_entities = []## Fill missing codes and track matchesdef fill_code_and_track(row):if pd.isna(row["Code"]): matched_code = entity_to_code_map.get(row["Entity"])if matched_code isnotNone: matched_entities.append(row["Entity"])return matched_codeelse: unmatched_entities.append(row["Entity"])returnNonereturn row["Code"]all_data["Code"] = all_data.apply(fill_code_and_track, axis=1)## Remove duplicates from tracking listsmatched_entities =sorted(set(matched_entities))unmatched_entities =sorted(set(unmatched_entities))print("✅ Finished filling missing Code values.")print(f"✅ {len(matched_entities)} entities were successfully matched:")for entity in matched_entities:print(" ✓", entity)print("\n❗ Entities with no Code found:")for entity in unmatched_entities:print(" ✗", entity)print(f"\n🧮 Remaining rows with missing Code: {all_data['Code'].isna().sum()}")## As we can see for these countries, we do not have code, please let mw know, what should we do for them
✅ Finished filling missing Code values.
✅ 0 entities were successfully matched:
❗ Entities with no Code found:
✗ Arab World (WB)
✗ Argentina (urban)
✗ Bolivia (urban)
✗ Central Europe and the Baltics (WB)
✗ China (rural)
✗ China (urban)
✗ Colombia (urban)
✗ EU (27)
✗ East Asia and Pacific (WB)
✗ East Asia and the Pacific (WB)
✗ Ecuador (urban)
✗ Ethiopia (rural)
✗ Europe and Central Asia (WB)
✗ European Union (27)
✗ Faeroe Islands
✗ High-income countries
✗ Honduras (urban)
✗ India (rural)
✗ India (urban)
✗ Latin America and Caribbean (WB)
✗ Low-income countries
✗ Lower-middle-income countries
✗ Micronesia (country) (urban)
✗ Middle East and North Africa (WB)
✗ Middle-income countries
✗ North America (WB)
✗ Rwanda (rural)
✗ South Asia (WB)
✗ Southern and Eastern Africa (WB)
✗ Sub-Saharan Africa (WB)
✗ Suriname (urban)
✗ Upper-middle-income countries
✗ Uruguay (urban)
✗ Western and Central Africa (WB)
🧮 Remaining rows with missing Code: 1019
## So I just created my base table based on Year and Country and filtered it out for Year > 2000 and <= 2023filtered_data = all_data[(all_data["Year"] >2000) & (all_data["Year"] <=2023)]base_table = filtered_data[["Year", "Entity", "Code"]].drop_duplicates()base_table = base_table.sort_values(by=["Year", "Entity"]).reset_index(drop=True)base_table
Year
Entity
Code
0
2001
Afghanistan
AFG
1
2001
Albania
ALB
2
2001
Algeria
DZA
3
2001
Andorra
AND
4
2001
Angola
AGO
...
...
...
...
5265
2023
Vietnam
VNM
5266
2023
World
OWID_WRL
5267
2023
Yemen
YEM
5268
2023
Zambia
ZMB
5269
2023
Zimbabwe
ZWE
5270 rows × 3 columns
merged_wide_df = base_table.copy()datasets = {"censorship": df_censorship,"employment": df_employment_discrimination,"gini": df_gini,"gdp": df_gdp,"education": df_education,"gendercare": df_gender_care,"marriage": df_marriage,"legalgender": df_legal_gender,}for name, df in datasets.items(): value_cols = [col for col in df.columns if col notin ["Entity", "Year"]] df_renamed = df.rename(columns={col: f"{col}_{name}"for col in value_cols}) merged_wide_df = merged_wide_df.merge( df_renamed, on=["Entity", "Year"], how="left" )print("Final shape:", merged_wide_df.shape)
Final shape: (5270, 20)
merged_wide_df.head()
Year
Entity
Code
Code_censorship
Censorship of LGBT+ issues (historical)_censorship
GDP per capita, PPP (constant 2021 international $)_gdp
Code_education
Public spending on education as a share of GDP_education
Code_gendercare
Gender-affirming care (historical)_gendercare
Code_marriage
Same-sex marriage (historical)_marriage
Code_legalgender
Right to change legal gender (historical)_legalgender
0
2001
Afghanistan
AFG
NaN
NaN
NaN
NaN
NaN
NaN
NaN
AFG
1454.1108
NaN
NaN
NaN
NaN
AFG
Banned
NaN
NaN
1
2001
Albania
ALB
NaN
NaN
NaN
NaN
NaN
NaN
NaN
ALB
7215.8200
ALB
3.4587
NaN
NaN
NaN
NaN
NaN
NaN
2
2001
Algeria
DZA
DZA
Imprisonment as punishment
NaN
NaN
NaN
NaN
NaN
DZA
11742.5950
NaN
NaN
NaN
NaN
DZA
Banned
NaN
NaN
3
2001
Andorra
AND
NaN
NaN
NaN
NaN
NaN
NaN
NaN
AND
59109.0160
NaN
NaN
AND
Restricted
NaN
NaN
NaN
NaN
4
2001
Angola
AGO
NaN
NaN
NaN
NaN
NaN
NaN
NaN
AGO
6049.1630
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
print("Long format shape:", merged_wide_df.shape)
Long format shape: (5270, 20)
list(merged_wide_df.columns)
['Year',
'Entity',
'Code',
'Code_censorship',
'Censorship of LGBT+ issues (historical)_censorship',
'Code_employment',
'LGBT+ employment discrimination (historical)_employment',
'Code_gini',
'Gini coefficient_gini',
'990179-annotations_gini',
'Code_gdp',
'GDP per capita, PPP (constant 2021 international $)_gdp',
'Code_education',
'Public spending on education as a share of GDP_education',
'Code_gendercare',
'Gender-affirming care (historical)_gendercare',
'Code_marriage',
'Same-sex marriage (historical)_marriage',
'Code_legalgender',
'Right to change legal gender (historical)_legalgender']
# Drop all columns that start with 'Code_'merged_wide_df = merged_wide_df.loc[:, ~merged_wide_df.columns.str.contains("Code_")]list(merged_wide_df.columns)
['Year',
'Entity',
'Code',
'Censorship of LGBT+ issues (historical)_censorship',
'LGBT+ employment discrimination (historical)_employment',
'Gini coefficient_gini',
'990179-annotations_gini',
'GDP per capita, PPP (constant 2021 international $)_gdp',
'Public spending on education as a share of GDP_education',
'Gender-affirming care (historical)_gendercare',
'Same-sex marriage (historical)_marriage',
'Right to change legal gender (historical)_legalgender']
GDP per capita, PPP (constant 2021 international $)_gdp
Public spending on education as a share of GDP_education
Gender-affirming care (historical)_gendercare
Same-sex marriage (historical)_marriage
Right to change legal gender (historical)_legalgender
5265
2023
Vietnam
VNM
NaN
NaN
NaN
NaN
13491.8800
NaN
Legal
Banned
Legal, surgery required
5266
2023
World
OWID_WRL
NaN
NaN
NaN
NaN
20670.9410
NaN
NaN
NaN
NaN
5267
2023
Yemen
YEM
NaN
NaN
NaN
NaN
NaN
NaN
NaN
Banned
NaN
5268
2023
Zambia
ZMB
Imprisonment as punishment
NaN
NaN
NaN
3673.4841
NaN
NaN
Banned
NaN
5269
2023
Zimbabwe
ZWE
Imprisonment as punishment
NaN
NaN
NaN
3442.2512
NaN
NaN
Banned
NaN
print(cleaned_long_df.columns.tolist())
['Year', 'Entity', 'Code', 'Censorship of LGBT+ issues (historical)_censorship', 'LGBT+ employment discrimination (historical)_employment', 'Gini coefficient_gini', '990179-annotations_gini', 'GDP per capita, PPP (constant 2021 international $)_gdp', 'Public spending on education as a share of GDP_education', 'Gender-affirming care (historical)_gendercare', 'Same-sex marriage (historical)_marriage', 'Right to change legal gender (historical)_legalgender']
cleaned_long_df.columns = ( cleaned_long_df.columns .str.replace("Entity", "country", regex=False) .str.replace("Year", "year", regex=False) .str.replace("Code", "country-code", regex=False) .str.replace("Censorship of LGBT+ issues (historical)_censorship", "lgbtq-censorship", regex=False) .str.replace("LGBT+ employment discrimination (historical)_employment", "employment-discrimination", regex=False) .str.replace("Gini coefficient_gini", "gini-index", regex=False) .str.replace("GDP per capita, PPP (constant 2021 international $)_gdp", "gdp-per-capita", regex=False) .str.replace("Public spending on education as a share of GDP_education", "education-spending-gdp", regex=False) .str.replace("Gender-affirming care (historical)_gendercare", "gender-affirming-care", regex=False) .str.replace("Same-sex marriage (historical)_marriage", "same-sex-marriage", regex=False) .str.replace("Right to change legal gender (historical)_legalgender", "legal-gender", regex=False))
## Again Dropping some columns based on Non-Null %columns_to_drop = ['990179-annotations_gini']cleaned_long_df = cleaned_long_df.drop(columns=columns_to_drop)
## One more time checking the columns eda_summary = pd.DataFrame({"Non-Null Count": cleaned_long_df.notnull().sum(),"Total Rows": len(cleaned_long_df),"Non-Null %": cleaned_long_df.notnull().mean() *100,"Data Type": cleaned_long_df.dtypes})eda_summary = eda_summary.sort_values(by="Non-Null Count", ascending=False)eda_summary["Non-Null %"] = eda_summary["Non-Null %"].round(1)eda_summary.reset_index(inplace=True)eda_summary.rename(columns={"index": "Column"}, inplace=True)eda_summary
#3 Checking for each country, how many missing values we have for each column summary = cleaned_long_df.groupby("country").agg( total_rows=("country", "size"), missing_gdp_per_capita=("gdp-per-capita", lambda x: x.isna().sum()), missing_same_sex_marriage=("same-sex-marriage", lambda x: x.isna().sum()), missing_legal_gender=("legal-gender", lambda x: x.isna().sum()), missing_lgbtq_censorship=("lgbtq-censorship", lambda x: x.isna().sum()), missing_employment_discrimination=("employment-discrimination", lambda x: x.isna().sum()), missing_gender_affirming_care=("gender-affirming-care", lambda x: x.isna().sum()))summary["missing_count"] = ( summary["missing_gdp_per_capita"]+ summary["missing_same_sex_marriage"]+ summary["missing_same_sex_marriage"] + summary["missing_legal_gender"]+ summary["missing_lgbtq_censorship"]+ summary["missing_employment_discrimination"]+ summary["missing_gender_affirming_care"]+ summary["missing_legal_gender"] )summary_sorted = summary.sort_values("missing_count", ascending=False)summary_sorted[summary_sorted["missing_count"] >100] ###
total_rows
missing_gdp_per_capita
missing_same_sex_marriage
missing_legal_gender
missing_lgbtq_censorship
missing_employment_discrimination
missing_gender_affirming_care
missing_count
country
Western and Central Africa (WB)
22
22
22
22
22
22
22
176
Argentina (urban)
21
21
21
21
21
21
21
168
EU (27)
21
21
21
21
21
21
21
168
Central Europe and the Baltics (WB)
21
21
21
21
21
21
21
168
Bermuda
23
0
23
23
23
23
23
161
...
...
...
...
...
...
...
...
...
Sint Maarten (Dutch part)
15
0
15
15
15
15
15
105
Albania
23
0
2
23
23
9
23
105
Georgia
23
0
23
0
23
13
23
105
Malta
23
0
13
14
23
3
23
103
Cameroon
23
0
0
23
9
23
23
101
140 rows × 8 columns
## Based on the top table, some countries have missing values for almost all columns, so we are going to delete them instead of deleting the columnscountries_to_exclude = summary_sorted[summary_sorted["missing_count"] >100].index.tolist()cleaned_long_df = cleaned_long_df[~cleaned_long_df["country"].isin(countries_to_exclude)]cleaned_long_df = cleaned_long_df.reset_index(drop=True)cleaned_long_df.head()
year
country
country-code
lgbtq-censorship
employment-discrimination
gini-index
gdp-per-capita
education-spending-gdp
gender-affirming-care
same-sex-marriage
legal-gender
0
2001
Algeria
DZA
Imprisonment as punishment
NaN
NaN
11742.60
NaN
NaN
Banned
NaN
1
2001
Andorra
AND
NaN
NaN
NaN
59109.02
NaN
Restricted
NaN
NaN
2
2001
Argentina
ARG
NaN
NaN
NaN
21066.46
4.83
NaN
NaN
NaN
3
2001
Armenia
ARM
NaN
NaN
0.35
5044.12
2.47
Legal, but restricted for minors
NaN
Legal, surgery required
4
2001
Australia
AUS
Varies by region
NaN
0.33
44667.93
5.22
Legal
NaN
Varies by region
## One more time checking the columns eda_summary = pd.DataFrame({"Non-Null Count": cleaned_long_df.notnull().sum(),"Total Rows": len(cleaned_long_df),"Non-Null %": cleaned_long_df.notnull().mean() *100,"Data Type": cleaned_long_df.dtypes})eda_summary = eda_summary.sort_values(by="Non-Null Count", ascending=False)eda_summary["Non-Null %"] = eda_summary["Non-Null %"].round(1)eda_summary.reset_index(inplace=True)eda_summary.rename(columns={"index": "Column"}, inplace=True)eda_summary